Millions are able to build AI apps with cloud APIs with natural language now. Yet their phone's AI chip sits mostly idle. Despite Apple and Microsoft's 2024 promises of on-device AI, we're still waiting. Where's the intelligence in Apple Intelligence? What happened to Windows Recall?
"We're kind of like in this 1960-ish era where LLM compute is still very expensive for this new kind of computer and that forces the LLMs to be centralized in the cloud and we're all just thin clients that interact with it over the network... the personal computing revolution hasn't happened yet because it's just not economical."
— Andrej Karpathy, YC Startup School 2024
Just as personal computers democratized computing by moving it from centralized mainframes to individual devices, AI needs its own personal computing revolution.Cloud computing will not be replaced; the industry relies on cloud computing more than ever, but more AI workloads need to be available on a personal device for it to be personal.
After eight months building a local-first meeting transcriber across macOS, iOS, and Windows, and a year before that building cloud AI agents, deploying AI locally is 10x harder than using cloud services. Despite the cost and privacy benefits of local AI, there hasn't been a breakout app yet. The ecosystem is too fragmented, and everyone is playing catch-up on the model layer.
There's a lot to discuss, but before that, it's worth looking at how we got here.
The CNN era
We've had AI features on our devices for years. Features like Face ID, fingerprinting, and object detection are all powered by machine learning models. Before transformer models became mainstream, the majority of models that ran on edge devices were convolutional neural networks (CNN) models like MobileNet, EfficientNet-Lite, and YOLO. They were exceptionally good at very specific tasks that involved vision.
Most of your devices have a CPU, GPU, and more recently an AI accelerator, all embedded onto a single SoC (System on Chip) in your devices. CNN models can run on any of these, but if there's a task you have to perform billions or even trillions of times per day, one should optimize it.
CPUs are very general purpose and offer a lot of flexibility at the cost of performance. As graphical interfaces became more popular, it became clear that real-time graphics rendering was too intensive for CPUs, and that's how GPUs were originally born. CPUs may have tens of cores, but a GPU will have thousands of smaller streamlined cores, making them extremely good at parallel processing.
At one point we had ~200 models powering our iPhones for tasks like object detection, classification, OCR; likely even more now. Like how CPUs could technically handle graphical rendering, GPUs can handle operations for CNN models as well. In fact, GPUs still excel for model training, and they're still the de facto choice for cloud AI inferencing. However, GPUs are extremely power hungry for edge devices, and that's why AI accelerators are needed. There are different marketing terms for AI Accelerators, but they’re commonly known as Neural Processing Units (NPUs); Apple calls them Apple Neural Engines (ANE).
NPUs were originally designed specifically to only run CNN model operations as efficient as possible. They use less precise math (like int8 or fp16) instead of the full precision (fp32) that GPUs and CPUs use. This trade-off gives much better performance if the model can handle lower precision calculations.
The benefits are quite obvious. You can see from this benchmark the significant difference when running a stable diffusion model: you get 4-6x more battery life on the NPU. Research has shown that NPUs are much more effective for edge AI computing and mobile applications, especially real-time and long running tasks. In practice, one should expect 2-3x battery life improvements when running on NPU as some operations tend to fall back to CPU due to a lack of support.

Running Stable Diffusion on an NPU delivers 4-6x better battery life than on GPU
This NPU-CNN pairing worked well for a couple of years since most models running on the edge were built on CNN and most models deployed were vertically integrated. Apple, Google, and Samsung designed the chips, the models, and the features that the models powered. However, ChatGPT in 2023 disrupted the entire NPU ecosystem as the appetite for AI features grew.
The “large” language model disruption
Even though transformer models were popular back in 2018 with models like BERT and RoBERTa being widely used in natural language processing. It's fair to say that ChatGPT's success caught the industry off-guard and brought transformer models mainstream. Suddenly, models weren't measured in millions of parameters but billions. MobileFaceNet for Android face-unlock uses 0.99M parameters. GPT-3 has 175B. That's a 176,000x increase. ChatGPT's success wasn't just about text generation, it validated transformers as the architecture for the next wave of advanced models. Within months, we saw Stable Diffusion democratize image generation, GPT-4V enabled visual understanding, and Whisper transform speech recognition.
For edge devices, this meant rethinking everything; camera apps that could describe scenes for the visually impaired, voice assistants that actually understood context, AR applications with spatial reasoning, and creative tools that generated content locally. While some workloads like training, large-scale inference would always need cloud resources, chipmakers recognized that bringing transformer capabilities to edge devices would unlock entirely new product categories.

Chipmakers scrambled to catch up, pouring investments into NPUs with ever-higher TOPS
Chipmakers scrambled to catch up, pouring investments into NPUs to push TOPS (Trillions of Operations Per Second). Going from models with a few million parameters to models with hundreds of billions wasn't just a scaling problem; it was a fundamental shift. Unlike classic neural networks, transformer-based models are far more dynamic; their inputs, outputs, and computation graphs can vary significantly, requiring new operations and memory patterns that NPUs weren't originally built to handle. Even when hardware supports parts of the model, precision-sensitive layers like softmax, LayerNorm, or attention often need higher numerical accuracy (e.g., FP32), which most NPUs do not support, forcing fallback to CPU or GPU and breaking the performance gains of full offloading.
The hardware designed for static CNN operations now had to support dynamic transformers that were thousands of times larger in memory. Supporting them is technically possible, but requires a lot of work.
Deployment complexity
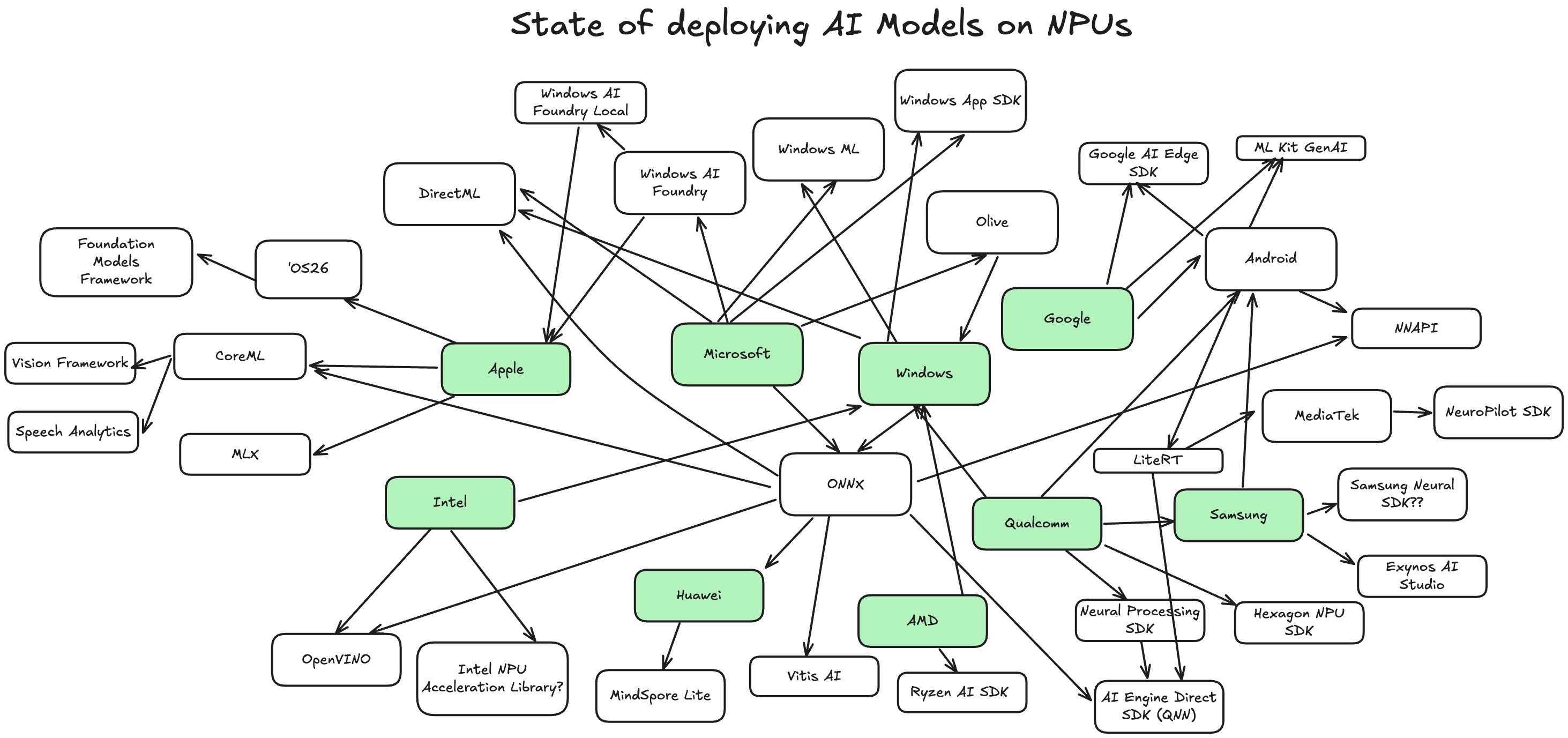
A 'simple' meeting note-taker today needs five different AI models: speech recognition, speaker embedding, speaker segmentation, language models for summarization and voice activity detection. What used to be optional features have become the core of modern AI apps. AI has moved from being a nice-to-have add-on to becoming central to the core experience of AI native applications.
Deploy these five models across platforms and suddenly you're dealing with 25 model-to-NPU conversions. Five models with five different NPU architectures (Apple Neural Engine, Qualcomm Hexagon, Intel NPU, AMD XDNA, Google Tensor). For larger models like speech recognition and summarization, you need to offer different variants based on the hardware so 25 is just the minimum.
The conversion timeline is brutal. Whisper-v3-turbo released in October 2024. Qualcomm just released support for it to run on their NPU in June 2025. By the time support arrives, newer models have already taken the (automatic speech recognition) ASR leaderboard. State-of-the-art (SOTA) is being redefined every quarter.

ASR leaderboard showing how quickly models evolve and surpass each other
Each new model requires platform-specific model optimization, performance validation against GPU versions, energy consumption testing, and native language bindings. 80% of our engineering time went to the model layer alone. Meanwhile, the industry compounds the problem with constant churn: Microsoft rebranded their local AI solution four times in one year, Apple's new frameworks only work on their latest devices, and Copilot+ PCs heavily prefer Qualcomm devices.
The pace of model improvement makes the fragmentation worse. GPT-4o (May 2024) uses an estimated 200B parameters. But smaller models are catching up fast, we'll likely see GPT-4o performance in sub-5B parameter models by 2026. Each breakthrough brings new operations that NPUs must support. Each NPU requires new APIs. Each API needs framework integration. The cycle never ends. Even NVIDIA researchers argue "Small Models are the Future of Agentic AI".

Performance comparison showing how Small Language Models are catching up to larger models
Historical context
This fragmentation problem isn't unique to NPUs; we've seen this pattern before. The 1970s minicomputer revolution forced developers to choose between incompatible architectures. When Apple moved to ARM, Docker's desktop app official support took 6 months. There are still different CPU architectures, but the problem has mostly been mitigated by solutions like LLVM or the "write once, run anywhere" promise of the likes of Java and Docker.
Running models on GPUs isn't a solved problem either. While NVIDIA's CUDA has become the de facto standard, developers still struggle with compatibility across different GPU generations, memory limitations, and the complexity of optimizing models for specific hardware. Even with CUDA's dominance, getting optimal performance requires deep expertise and careful tuning.
The machine learning community has been working on a solution: unified compiler frameworks that can translate AI models to run efficiently on any hardware. Think of these as the "LLVM for AI" - just as LLVM lets programmers write code once and compile it for different CPUs, these ML compilers aim to let developers train a model once and deploy it anywhere.
Two major projects lead this effort. Apache TVM, started at the University of Washington, creates optimized code for different hardware targets. MLIR (Multi-Level Intermediate Representation), developed at Google, takes a more flexible approach with its "dialect" system that can represent AI computations at different levels of abstraction. Both promise to solve the fragmentation problem by automatically optimizing models for whatever hardware you have.
However, both approach support still relies on hardware vendors either exposing the right interfaces or contributing optimizations back to these projects. Both are slow processes. With SOTA models emerging every few months with new operations, it will take years before we see comprehensive support if we solely rely on these unified runtimes.
And what happens when transformers get replaced? Do we restart this cycle with the next architecture?
The problem isn't just technical; it's economic and threatens AI democratization itself. Each hardware target requires specialized expertise, dedicated testing infrastructure, and ongoing maintenance as models and hardware evolve. For most developers, this overhead makes NPU optimization economically unfeasible despite the compelling efficiency gains.
AI-driven Deployment
We don't need another compiler or framework. We need AI to solve its own deployment problem. We've been down that road before with LLVM, Java, and countless other "write once, run anywhere" promises. This time, we have something new: AI itself.
Coding agents are already writing production code, fixing bugs, and even architecting systems. Why not apply that same intelligence to the model deployment problem? Instead of waiting years for vendors to support new operations, an AI agent could analyze a PyTorch model, understand the target NPU's capabilities, and automatically generate the conversion code. When it hits a limitation, it doesn't give up; it finds workarounds, optimizes differently, or falls back gracefully.
Using AI for deployment isn't pie-in-the-sky thinking. We've already used a prototype agent to get speaker diarization models running on Apple's ANE, achieving significant efficiency gains over CPU. The agent patched PyTorch code, worked around unsupported operations, and delivered a model that actually ships in production. We are able to take matters into our own hands.
The key insight is that model optimization is fundamentally a pattern-matching problem with lots of edge cases. That's exactly what AI excels at. Feed it telemetry data, benchmark results, and hardware constraints, and it learns. When a new model architecture emerges, it develops optimization strategies. For operations not supported by the NPU, we can fall back to the CPU until vendors add support.The fragmentation problem becomes a data problem, and data problems are solvable.
The path forward
Cloud AI won't disappear, just like cloud computing didn't kill on-premise servers. But the physics are undeniable: moving compute closer to data is always more efficient. Your phone recording a meeting shouldn't need to stream audio to a data center for transcription. Your laptop shouldn't need an internet connection to summarize a document. You cannot have ambient computing if it doesn’t work without the internet. These aren't radical ideas; they're obvious ones held back by implementation complexity.
The mainframe-to-PC transition took nearly two decades. We don't have that kind of time. The demand for AI is here now, privacy concerns are mounting, and edge hardware is already capable. As models eat more into the application code logic, what we need isn't more powerful chips or better frameworks. We need to stop treating model deployment like it's 1999, where every platform required manual optimization.
Deploying models to the edge needs to be as simple as deploying application code. Developers will choose between cloud and edge based on their use case, not technical limitations. The hardware exists. The models are small enough. The missing piece is deployment—and AI itself might be the answer.